HLS ( High-Level Synthesis ) 는 복잡한 알고리즘을 좀더 쉽게 IP로 만들수 있도록 C나 C++을 이용하여 프로그래밍 할 수 있는 도구, HDL에 비해 구현이 용이함.
Xilinx에서 제공하는 튜토리얼 문서

Vivado HLS Command Prompt -> vivado_hls -f run_hls.tcl
tcl파일로 프로젝트를 생성하는 모습
> vivado_hls -p dct_prj
만들어진 프로젝트를 hls로 실행
예제 샘플코드는 DCT ( Discrete Cosine Transform ) 를 이용해서 PYNQ의 FPGA를 이용해 하드웨어가 가속이 됨을 확인하는 과정을 담았다.

DCT의 경우 이렇듯 중복 For문이 많아 FPGA의 병렬 연산을 이용해 효율적이고 빠른 연산을 수행 할 수 있을 것이다.
Synthesis 후 시스템의 레이턴시를 확인 할 수 있다.

시스템의 레이턴시가 2935 클락이 나오는 것을 확인 하였다.
instance의 레이턴시와 인터벌값은 한 함수가 끝나고 다음실행까지의 간격을 의미한다.
루프를 보면 각각 리드와 라이트에 144사이클이 필요함을 알 수 있다.
이니시에이션 인터벌이 존재하지 않기 때문에 레이턴시는 이터레이션 레이턴시 18을 8번 돌려서 생긴 결과이다.

dct 2d 내부지연을 살펴보았다, 지금까지 살펴본 지연들이 얼마나 감소하는지 살펴볼 것이다.

Directive에서 Inner Loop를 더블클릭해 HLS파이프라인을 적용

적용이 완료되면 , Synthesis를 통해 결과를 확인한다

그 결과, 레이턴시가 2935에서 1723으로 대폭 감소한 것을 확인 할 수 있다.
파이프라인이 뭔지 사진을 통해 알아보자,

파이프라인을 통해 for루프를 병렬처리 할 수 있도록 하여 빠른 연산이 가능하게 되는 것이다.
이터레이션이 시작되고연산중에 다음 이터레이션을 시작할 수 있는 것이 파이프라이닝이다. 따라서 전체의 레이턴시가 감소 할 수 있다.

아우터 루프에도 파이프라인을 적용해 보았다.

더 획기적으로 레이턴시가 감소하였다. 이는 해당 함수가 여러번 호출되기 때문에 더 큰 효과를 본경우이다.
이렇듯 많이 호출되고 많이 반복되는 루프에 적적하게 파이프라인을 넣어줌으로써 레이턴시를 크게 감소 시킬 수 있음을 알 수 있다.
다음은 블럭 램을 파티셔닝하여 얼마나 레이턴시가 감소하는지 알아 보도록 하겠다.


이번에는 inbuf에 파티션을 주고 디멘션을 2로 설정하겠다.

파티션을 나누었더니 레이턴시가 더 감소하게 되었다.

파티션을 나눔으로써 기존에 한개였던 배열에 좀더 쉽게 개별적으로 접근 할 수 있게 되어 레이턴시가 감소하였다.
이번에는 HLS 데이터 플로우를 적용해 보도록 하겠다.

Synthesis 결과
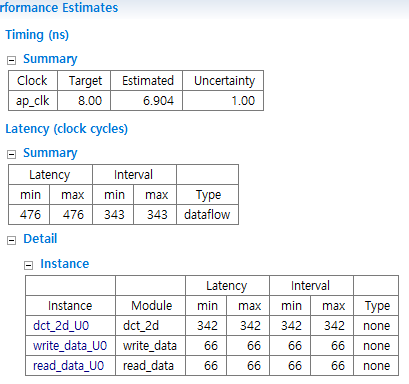
인터벌이 감소하게 되었다. DataFlow pragma는 task-level에서 pipelining을 가능하게 하여 기능과 루프가 작동 중에 겹치도록 하여 RTL 구현의 동시성을 높이고 디자인 전체의 처리량을 증가시킨다.
이번에는 HLS INLINE을 적용시켜보도록 한다.
결과

인터벌이 매우 줄어들게 된다. 인라인을 사용하게 되면 hierarchy구조에서 계층구조를 약하게해 하위구조에서 수행할 작업을 상위 탑 모둘에서 수행하는 것과 같은 결과를 일으킨다. 그럼 DataFlow가 하위에도 적용된것과 같아 인터벌이 매우 감소한다.
이렇게 레이턴시와 인터벌을 무작정 감소시킨다 해도, 무작정 좋기만 한 것은 아닌데,

이런 결과로 레이턴시와 인터벌이 같아지거나 거의 비슷하면 하나가 끝날때 까지 거의 쉬고있다는 의미와 같으므로 병렬처리가 잘 이루어 지지 않을 것이다.
문제를 해결하기 위해 모든 루프를 파이프라인화 시켜도 되지만, 이는 회로가 매우 커질 위험이 있어 제대로된 옵티마이제이션이라고 할 수 없다.
따라서 탑모듈에서 데이터 플로우를 통해 함수의 병렬화를 해야한다.
'연구실 > PYNQ' 카테고리의 다른 글
| Vivado HLS Programming (0) | 2021.07.06 |
|---|---|
| PYNQ 고정 IP 보기, 세팅 ( PYNQ Static IP setting ) (0) | 2021.05.10 |